Over the past decade, machine learning (ML) has been applied successfully to a variety of tasks such as computer vision and natural language processing. Motivated by this, in recent years, researchers have employed ML techniques to solve code-related problems, including but not limited to, code completion, code generation, program repair, and type inference.
Dynamic programming languages like Python and TypeScript allows developers to optionally define type annotations and benefit from the advantages of static typing such as better code completion, early bug detection, and etc. However, retrofitting types is a cumbersome and error-prone process. To address this, we propose Type4Py, an ML-based type auto-completion for Python. It assists developers to gradually add type annotations to their codebases. In the following, I describe Type4Py’s pipeline, model, deployments, and the development of its VSCode extension and more.
Table of Contents
Type4Py
Overview
Before going into the detail of the Type4Py’s model and its implementation, it would be helpful to see the overview of Type4Py. In general, there is a VSCode extension at the client-side (developers) and the Type4Py model and its pipeline are deployed on our servers. Simply, the extension sends a Python file to the server and a JSON response containing type predictions for the given file is returned. In the following subsection, I describe each component.

Dataset
For an ML model to learn and generalize, there is a need for a large and high-quality dataset. Therefore, we created the ManyTypes4Py dataset which contains 5.2K Python projects and 4.2M type annotations. To avoid data leakage from the training set to the test set, we used our CD4Py tool to perform code de-duplication in the dataset. To know more about how we created the dataset, check out its paper.
Feature Extraction
As with most ML tasks, we need to find a set of relevant features in order to predict type annotations. Here, we consider features as type hints. Specifically, we extract three kinds of type hints, namely, identifiers, code context, and visible type hints (VTHs). To intuitively explain the type hints, consider below code snippet:
import numpy as np
def find_list_intersection(list_a, list_b):
intersec_list = []
for i in list_a:
if i in list_b:
intersec_list.append(i)
return np.array(intersec_list)
We use the function’s name, its parameters’ name, and variables’ name as type hints to predict types. Considering code context, we consider the usage of parameters and variables in statements that they are used. VTHs are a deep recursive analysis of import statements in a file and its transitive dependencies in our dataset. Later on, we build a VTH vocabulary, which is used to give a hint to the model about the expected type.
Given the above code snippet, we create the following sequences for identifiers and code context to predict types of variables, parameters, and the function’s return:
# For identifiers
var_id_seq = ['intersec_list']
# Code context
var_cc_deq = ['intersec_list', 'append', 'i']
param_id_seq = ['list_a', 'find_list_intersection',
'list_b']
param_cc_seq = ['i', 'list_a']
# Guess the identifer and code context sequences
# for list_b!
ret_id_seq = ['find_list_intersection', 'list_a',
'list_b']
ret_cc_seq = ['np' 'array', 'intersec_list']
To learn from the extracted sequences, first, we apply common NL pre-processing techniques tokenization (by snake case), stop word removal and lemmatization. Then, we employ the famous Word2Vec model to generate word embeddings of the extracted sequences in order to train the Type4Py model, which is described next.
Model Architecture & Training
Before dive deep into the model’s details, an overview of the Type4Py model is shown below:
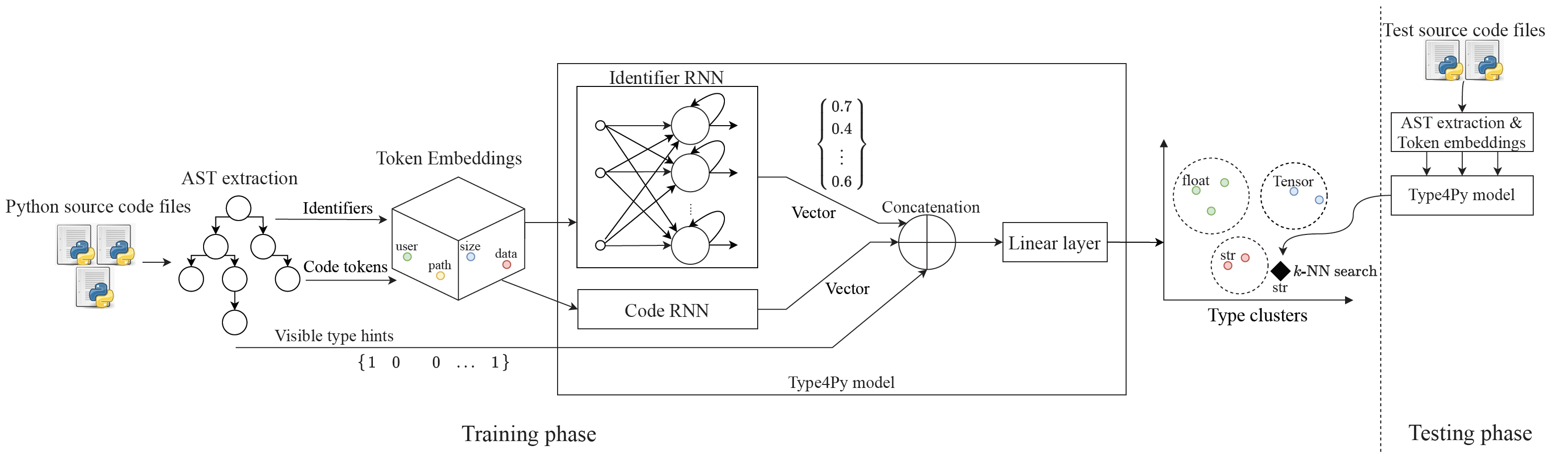
The Type4Py model is a hierarchical neural network, which consists of two RNNs with LSTM units, one for identifiers and another for code context. The basic idea is that two RNN captures different aspects of input sequences from both identifiers and code context. Next, the output of two RNNs is concatenated into a single vector, which is passed through a fully-connected linear layer. The final linear layer maps the learned type annotation into a high-dimensional feature space, called Type Clusters. In order to create Type Clusters, we need to formulate the type prediction task as a similarity learning problem, rather than a classification problem. Intuitively, the model learns to map similar types (say float) into its own type cluster and it should be as far as possible from the type cluster of other dissimilar types.
Considering the described similarity learning problem, the Type4Py model is trained using the Triplet loss function, which is recently used in computer vision for face recognition. Simply, the model receives three training examples, a to-be-learned type annotation (called anchor), a training example same as the anchor, a training example with a different type annotation from the first and second examples. For example, Let’s assume that the first training sample in the training set is the type annotation float plus its vector representations. Then, we randomly find a training sample with the float type annotation in the training and a training sample with a different type annotation. In this example, the triplet the model learns from would be (float, float, str).
After the model is trained and type clusters are obtained, to infer a type for a given query, we perform \(k\)-nearest neighbor (KNN) search in the type clusters to suggest a list of similar types for the given query. The value of \(k\) is \(10\) in both research and production environments.
Implementation
Our server-side components are all written in Python. To extract type hints, we first extract Abstract Syntax Trees (ASTs) and perform light-weight static analysis using our LibSA4Py package. NLP tasks are applied using NLTK. To train the Word2Vec model, we use the gensim package.
For the Type4Py model, we use bidirectional LSTMs in PyTorch to implement the two RNNs. To avoid overfitting, we apply the Dropout regularization to the input sequences. To minimize the value of the Triplet loss function, we employ the Adam optimizer. Also, to speed up the training process, we use the data parallelism feature of PyTorch, which distributes training batches among GPUs. For fast KNN search, we use Annoy.
To process type prediction requests from users, we implemented a tiny web application in Flask. It features type prediction using the Type4Py model, storing telemetry data from the VSCode extension (based on the user’s consent), and API rate limit. Lastly, we employ mypy to type-check the model’s predictions. However, as of this writing, the type-checking component is disabled for performance reasons. The Type4Py’s model and its server code are publicly available on GitHub here.
Deployment
To deploy the Type4Py model for the production environment, we convert the pre-trained PyTorch model to an ONNX model which allows us to query the model on both GPUs and CPUs with very fast inference speed and lower VRAM consumption. Thanks to Annoy, Type Clusters are memory-mapped into RAM from disk, which consumes less memory.
To handle concurrent type prediction requests from users, we employ Gunicorn‘s HTTP server with Nginx as a proxy. This allows us to have quite a number of asynchronous workers that have an instance of Type4Py’s ONNX model plus Type Clusters each. We use supervisor to manage and monitor the deployment.
We deployed the whole Type4Py’s server-side application on a Linux machine with Ubuntu distribution. The server has an Intel Xeon CPU with 28 threads, 128 GB of RAM, and two Nvidia GTX 1080 TIs. Lastly, we test our server’s production code with integration tests using GitHub Workflow.
VSCode Extension
The Type4Py’s VSCode extension is small and simple. Here is an overview of the extension workflow in VSCode:
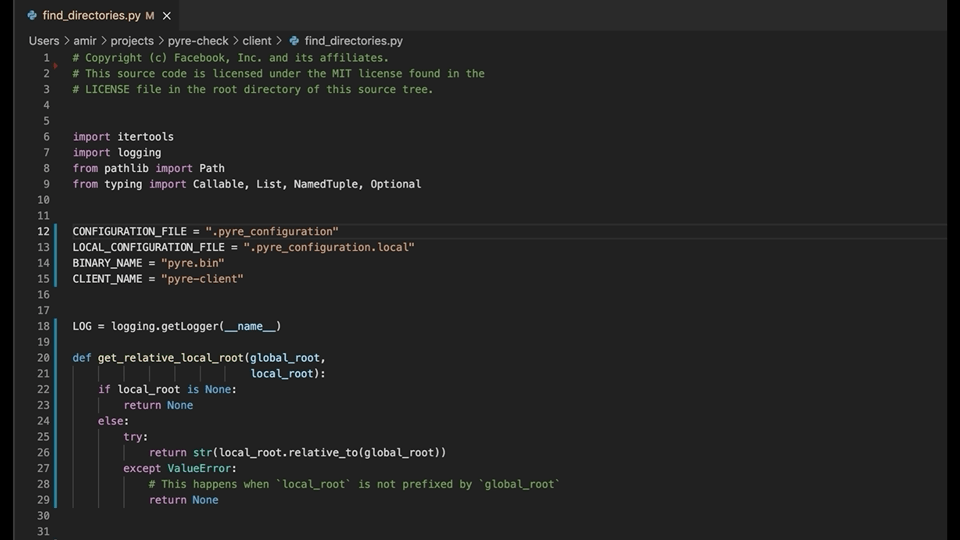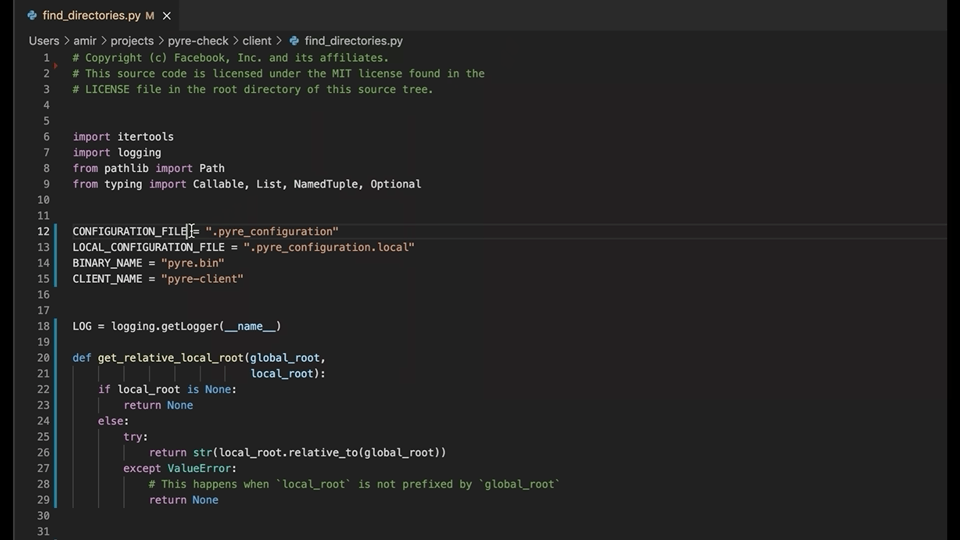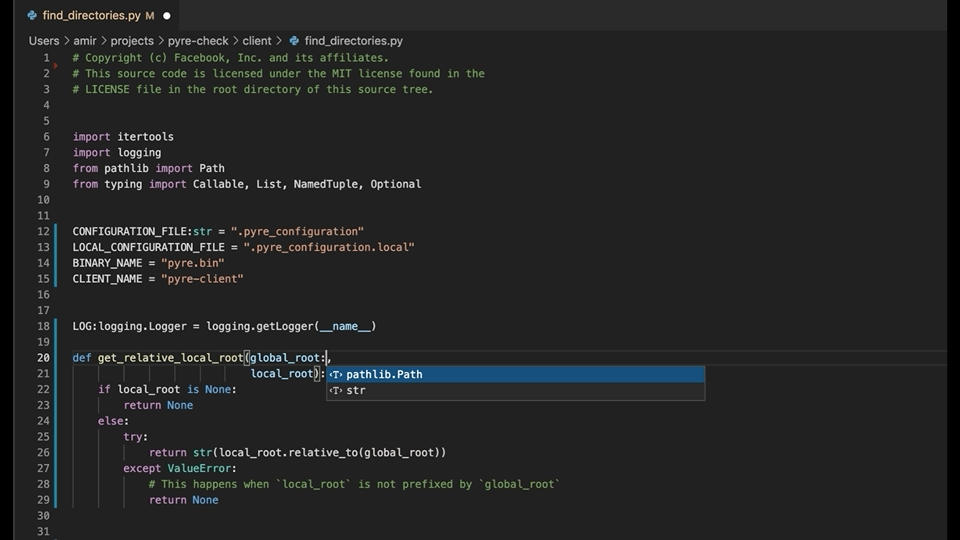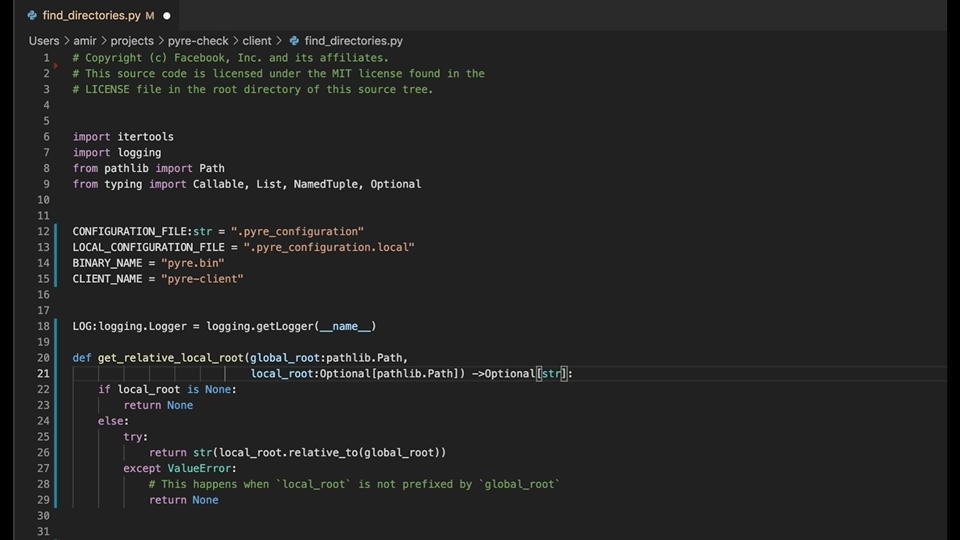
In general, to get type predictions, the extension sends an opened Python source file to the server and receives a JSON response. To implement the extension, we use the VSCode API in TypeScript. More specifically, we employ IntelliSense’s completion functionality and some pattern matching to locate type slots in the code for suggesting likely type annotations. Type slots are functions parameters, return types, and variables, which are located based on the line and column numbers. Currently, type prediction can be triggered via Command Pallete or by enabling the AutoInfer setting, which predicts types whenever a Python source file is opened or selected. Finally, the extension gathers telemetry data from users based on their consent. For instance, telemetry data contains which type predictions are accepted or rejected at a file’s type slots for research purposes and improving the Type4Py model. The Type4Py’s VSCode extension can be installed from the VS Marketplace here.
Releasing
We have two different environments for development and production as it is common in software development. In the development env., we test, debug, and profile Type4Py’s server-side components before releasing new features/fixes into the production code. Therefore, users will not be affected by new changes and features in the production env. Also, whenever we train a new Type4Py neural model, we test it against its evaluation metrics (see its paper) and run integration tests to ensure that it produces expected predctions for given Python source files. Finally, the VSCode extension uses the development env. when testing new featues/fixes before releasing a new extension version.
Roadmap
So far, I have described the current state of Type4Py. For future work, here is our roadmap:
- Enabling the type-checking process for the Type4Py’s predictions using mypy, preferably at the client-side.
- Releasing a local version of the Type4Py model and its pipeline that can be queried on users’ machines.
- Fine-tuning the (pre-trained) Type4Py model on users’ projects to learn project-specific types.
- Releasing a plugin for JetBrains PyCharm and a GitHub action or bot for adding type annotations to Python projects
Acknowledgments
The Type4Py model, its pipeline, and VSCode extension are all designed and developed at the Software Analytics Lab of SERG, Delft University of Technology. Our team consists of 4 researchers and developers, Amir M. Mir, Evaldas Latoškinas, Sebastian Proksch, Georgios Gousios. The Type4Py project has started in spring 2020 and it’s currently under active development and research.

References
Here are a few resources for further reading and research:
- Type4Py’s research paper
- ManyTypes4Py dataset’s paper (accepted at MSR’21)
- Type4Py’s VSCode Extension on the VS Marketplace
- LibSA4Py: Light-weight static analysis for extracting type hints and features
- CD4Py: Code De-Duplication for Python
- Development of VSCode Extensions
- Converting PyTorch models to ONNX format
- Type4Py vs. Tabnine: An ML-based type auto-completion comparison
- Machine Learning for Software Engineering research
Thanks for reading this blog post. I hope that it was useful and informative for readers. We would be glad to answer your questions and see your comments. Also, please share this blog post with your colleagues and friends if you think they might be interested.